
Natural Language Processing allows computers to accomplish the basics of the human action of language processing. Humans learn to process language in their first year of life. We listen to the speech patterns spoken around us, recognize sounds and associate them with meaning.
You may wonder, how can a machine process human language? We teach it.
By doing so, we save time, turning tasks that used to take an hour into a two-minute automation.
- What is Natural Language Processing?
- Why Does Natural Language Processing Matter?
- Who Can Use Natural Language Processing?
- Natural Language Processing Can Extract Data from Unstructured Documents
- How to Get Started with Natural Language Processing
What Is Natural Language Processing?
Natural Language Processing teaches software to understand human language. In the workplace, this means the ability to upload a document and have the computer read, understand and extract data into your systems.
Business analysts and end users – the people working with and processing the documents – can now train Natural Language Processing software with point-and-click functionality, whereas in the past they would have needed strong computer programming skills to do so.
Why Does Natural Language Processing Matter?
Natural Language Processing saves time.
For one lease document, instead of a human going through and picking out data elements and entering them into the computer manually, the machine will do it and put it into your systems. Where it used to take one hour to go through a single document, the computer can accomplish the same task in two minutes, beginning to end. We’ve seen one financial institution saved more than 5,000 hours annually with Natural Language Processing.
Who Can Use Natural Language Processing?
Natural Language Processing is useful to organizations that process large volumes of complex contracts. This can include (but is not limited to) organizations working in financial services, accounting or the legal field.
That Natural Language Processing can understand complex documents is important. While OCR technology can read structured and semi-structured documents (those with data in the same spot every time, or at least with reliable indicators on the page), unstructured documents are where Natural Language Processing shines.
In unstructured documents, there is no keyword or standardized structure on which to depend. Natural Language Processing will take care of completely unstructured documents with narrative, including lease agreements, contracts, loan documents and even email communications.
Natural Language Processing Can Extract Data from Unstructured Documents
Take a lease document for example: some header information may be similar from document to document, and some common language may exist within the documents, but the structure of each lease is completely dependent on who wrote it. Data could be in different places on each lease document. No two lease agreements are exactly the same.
To train Natural Language Processing to extract data from unstructured documents:
Step 1: Upload
To train the Natural Language Processing system to understand documents, you need to give it models of what documents might look like, something from which Natural Language Processing can learn. This can be achieved by uploading multiple examples of what the documents (these can be PDFs) may look like.
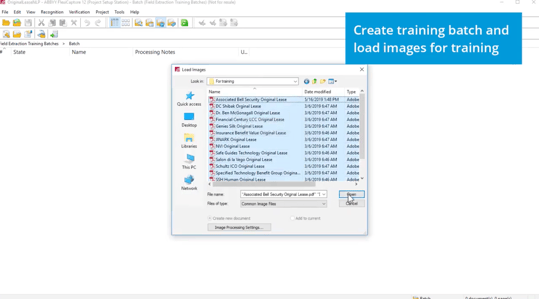
Step 2: Mark Up
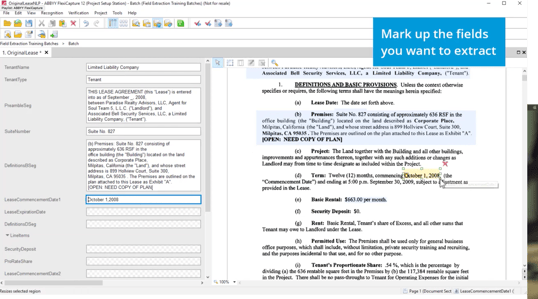
For each document (a sample lease agreement is shown below), teach the system to recognize various elements: Tenant Name, Tenant Type, Preamble Segment. Identify where each data element is on the page by dragging to highlight where these elements are. In doing so, you’re teaching the system where the information is. Dragging to highlight the data fills it into a text box (left side of image). The system will learn over time to fill the “LeaseCommencementDate1” field from where the document says “Term."
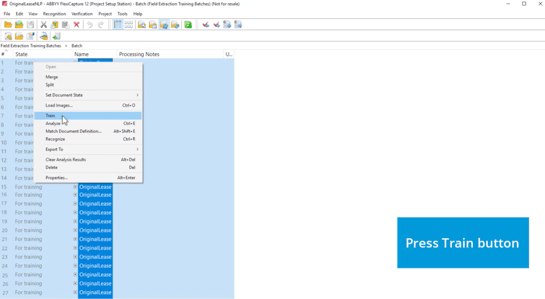
Step 3: Train
Once you've marked up and saved the document, click to submit to a training batch (in this case, your collection of other marked up lease documents). Then, you click “Train.” The system takes all the information you submitted and learns from it.
Training Natural Language Processing means uploading and marking up many examples of documents. This way, the system will learn from all of them. Now, when you upload a document not seen before, because of the training you already provided, it will extract the data fields you need, without you having to retrain.
How to Get Started with Natural Language Processing
Prior to getting started with any Natural Language Processing tool, we encourage you to do the following:
- Involve a subject matter expert in the early stages of implementation. This is someone who understands the data you need to extract and can help train the software to understand what you need.
- Provide representative data sets for model training. The more examples you or your subject matter expert can give the system to learn, the better it will be able to recognize and understand the data you need to extract.
- Start simple. Artificial intelligence learns over time. In the beginning, limit the number of fields you set up to ensure accuracy, then grow the number of fields you use over time. The mantra is to value continuous improvement over delayed perfection.
I’ll leave you with two questions: How many unstructured documents are you manually processing each year? And how much time are you wasting on processing these manually?
Loffler offers Natural Language Processing as a part of our ABBYY software, with an add-on called Flexicapture. (Screenshots above are courtesy of ABBYY’s demo video on the software.)
Learn More About Increasing Efficiency with Document Management
Read Next: What Is Document Management, Anyway?



